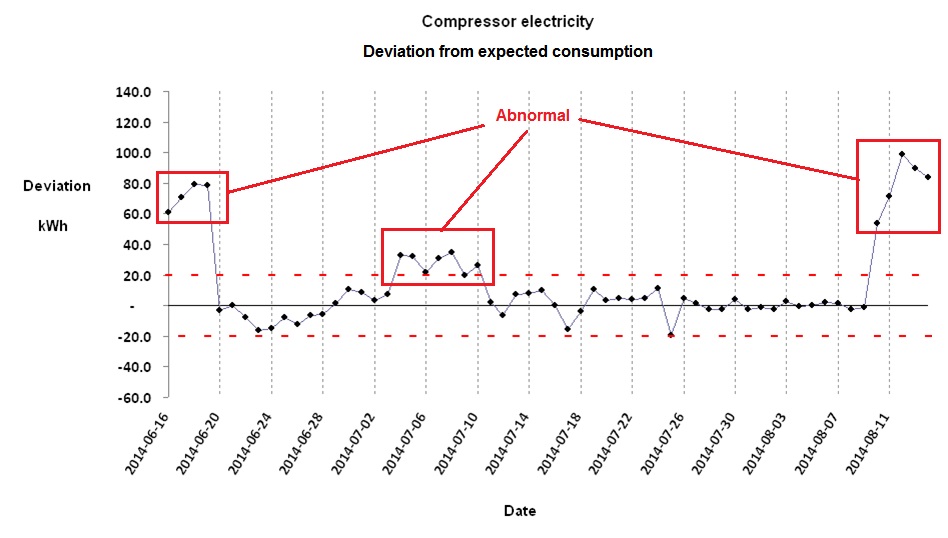
Updated 30/4/21 and 4//4/22
“Streamlined energy and carbon reporting” (SECR) is the term commonly used to describe the regime introduced with the Companies (Directors’ Report) and Limited Liability Partnerships (Energy and Carbon Report) Regulations 2018, Statutory Instrument 1155. This is not a self-contained set of regulations like ESOS; instead it consists of nothing but dozens of amendments to existing company reporting law. In short, undertakings covered by SECR simply need to collate annual total energy and emissions data and give them to their company secretary or accountant for inclusion in the annual report that they already have to prepare.
As this is an extension of financial reporting, compliance will be policed by the Financial Reporting Council, and not, as one might have thought, by the Environment Agency. The good news is that in terms of accuracy and completeness, your SECR reports need only be free of material misstatements, and according to the Government’s published guidance it is fine for a company to omit 2-5% of its energy or emissions if it considers them not to be material in the grand scheme of things.
Who is affected?
SECR applies to all quoted companies, and to unquoted companies and limited liability partnerships (LLP) which meet two of the following three criteria:
- At least 250 employees;
- £36 million annual turnover or more
- Balance sheet of £18 million or more
This is not quite the same as the ESOS regulations, in which an undertaking would be obliged to participate if it met criterion (1) alone.
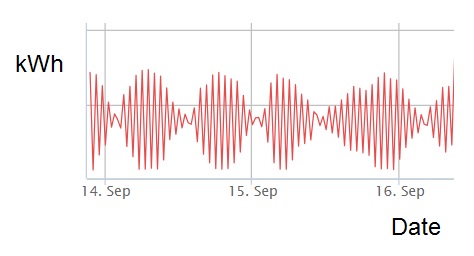
Undertakings which consumed less than 40,000 kWh in the year being reported do not have to report their actual figures but must still state that they fell below that threshold.
It is fine for a company to omit 2-5% of its energy or emissions if it considers them not to be material
Group reports should include the figures for all subsidiaries apart from those that would be exempt. Under these circumstances a subsidiary need not report its own figures although, of course, it will still need to collate the data for group use.
What must be reported?
The requirement covers energy use and greenhouse gas emissions arising from all use of electricity, gas, and transport fuels. Incidentally the definition of “gas” is not limited to natural gas, but refers to any gaseous fuel so it even includes hydrogen. The inclusion of electricity on an equal footing with other energy sources means that SECR differs from emissions reporting, in which fuels and pirchased electricity are considered under different ‘scopes’. Somewhat bizarrely liquid and solid fuels do not have to be accounted for, unlike in CRC (which SECR supposedly replaces) ESOS and EUETS. Bought-in heat, steam and cooling are included but not compressed air.
Quoted companies must report global figures, but LLPs and unquoted companies only have to declare UK consumption and emissions.
In the main, therefore, any undertaking that already keeps even very basic monthly fuel and electricity consumption records for its fixed assets will have no trouble collating the necessary energy data. Transport fuel, of course, is a different issue. As many an ESOS participant has found, transport fuel data are disproportionately hard to collect relative to its importance in the mix. Luckily, if you can reasonably assert that your transport energy and emissions are not material to the overall picture, you can just leave them out.
My advice would therefore be to look first at transport fuels, decide whether they are material, and if so put resources into capturing the data or estimating the figures.
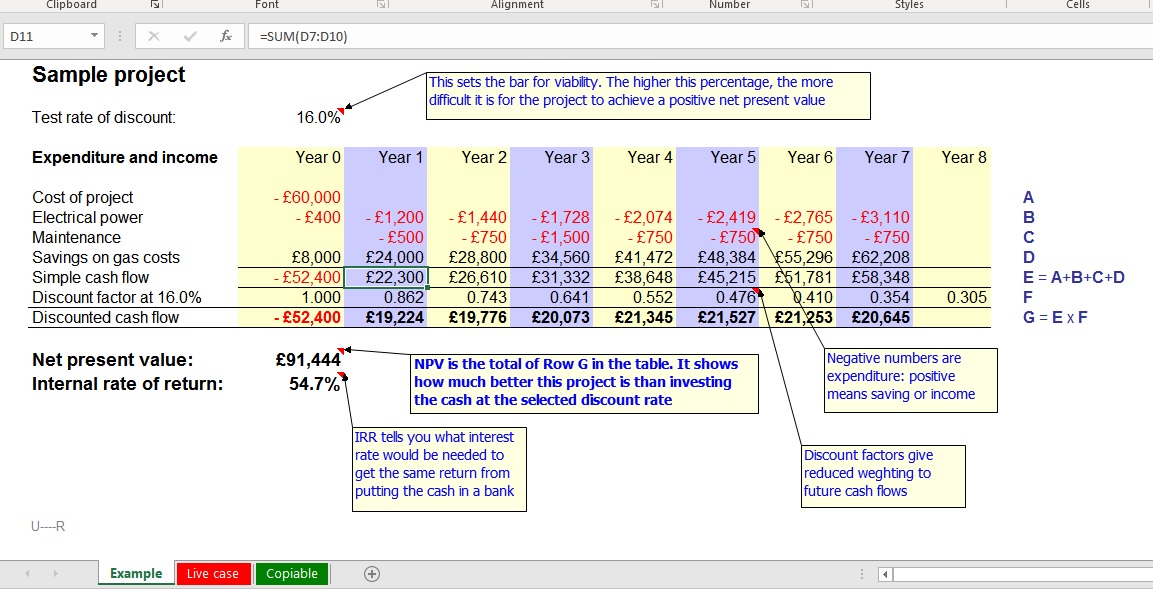
SECR requires emissions to be reported as well as energy consumptions. The necessary factors are published by the government and undertakings would be well advised to set up a methodical procedure for carrying out the calculations, because they must include details of their methodology alongside the data that they report.
Undertakings must report intensity metrics, of which an example would be kWh per unit of saleable product output. The idea is that stakeholders will be able to see, once a year, what progress the company is making in energy efficiency. This is actually a somewhat naïve and fanciful aim, given all the ways that such simple ratios can be distorted by external factors nothing to do with energy performance. Even more implausible is the idea of making ‘benchmarking’ comparisons between enterprises, but that is the government’s stated objective.
Companies are entitled not to report intensity metrics if, in their opinion, it would be prejudicial to their interests to do so. For example it might entail disclosing sensitive information about their sales volume. One option is to quote a metric based on financial turnover (which is already disclosed anyway). This may not be meaningful, but then neither is anything else they might report.
Finally, annual reports must now include descriptions of the principal measures taken to improve energy efficiency during the year in question, if there were any.
What is the compliance deadline?
Energy, emissions, intensity metrics and associated methodologies must be stated in annual reports covering accounting years starting in April 2019 or later, so by now all companies will have had full reporting years covered by the scheme (the last wave was for reporting years ending in February 2021). Actual report submission deadlines fall six months later for public companies, nine for private companies.
See links to SECR resources